
【評価・テスト】見えないものを測る Vol.4『データ分析』








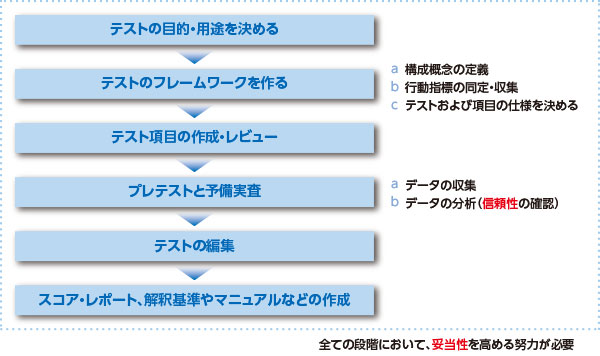
テスト作成のステップ
データの収集、本当にお疲れ様でした。
先生の研究所の方にもたくさんお世話になりました。ありがとうございました! プレテストも予備実査も、無事にデータが集まって本当によかったです。 先生、今回は、 予備実査の「データ分析」 ですよね。
データを分析して、テストの質をチェックする
はい。予備実査でたくさん収集した、このお宝データを分析していきます。テスト理論に基づいて、 項目とテストの質をチェックする 作業です。
せっかくなので、マナブさんもぜひ挑戦してみてください。まずは、データ分析の心得を掲げておきます。
- 正確かつ公正に
- やったことを明確に他人に示せるように
- 誰が分析しても同じ結果を再現できるように
そのために…
- 作業履歴が残るよう、なるべくスクリプトを用いて分析する
- データ値の手入力やコピー&ペーストなどは最低限にとどめ、それらも履歴として記録しておく
- なぜその分析をしたのか、根拠・目的を明確にする
先生、心得にある「スクリプト」って何でしたっけ?
データを分析するために書いたプログラムですね。データ分析は、簡単なものならエクセルなどの表計算ソフトでもできますが、私たちはたいてい、専用の統計ソフトを使います。メニュー画面から分析したいものをプルダウンなどで選んでいくソフトもありますが、私はスクリプトを書くタイプのものをお勧めします。同じスクリプトを使えば、何度やっても誰がやっても同じ分析を再現できますから。
先生、ハードルの高そうなことを、さらっと言いますね…。
あれ、そうですか? うーん、まあ、メニューから選んで操作するだけでも自動でスクリプトが作成されるものもありますので、最初はそれからでもいいかもしれませんが。
まあスクリプトを書けるようになるには、楽器と同じで、まずは慣れです。マナブさんも慣れれば大丈夫ですよ!
えっと、慣れるまで僕は分析をたくさんやり続ける前提ですね…。
はい! では、今回のデータのチェックと分析の概要をご紹介します。この内容で進めていきましょう。
- 回答の信用度が低いなどの理由で分析に含められないデータを除外(異常値・欠損値のチェック、回答パターンのチェック)
- スコアが極端に偏っていないか(目的に照らして妥当か)、分布をチェック
- 個々のテスト項目を、そのまま使えるか、改訂するか、破棄するかを、さまざまな統計指標から判断(項目分析)
- 信頼性係数と測定の標準誤差の確認
- テストのまとまり性の確認(因子分析)
- 分析結果とテストのフレームワークとの整合性の確認
項目を多めに30個用意していますが、確か、取捨選択していくのですよね。それが 「項目分析」 ですか?
そうです。たとえば、テストの1つひとつの項目とテスト全体の点数の 相関 を見たりします。相関って分かりますか?
はい、えっと、Aが高いとBも高いとか、相互に関係性があることですよね。
そのとおりです。テストは特定の概念を測るのに、複数の項目を使います。そのため、 テストの全体得点とテストの1つひとつの項目の得点は相関しているべき です。つまり、テストで測ろうとしている能力の高い人は、項目の1つひとつも高い得点を取っているべきです。もしそうなっていない項目があれば、その項目は能力を測る項目としてはふさわしくありません。できれば削除したいですね。そうしていくことが、全体的な 信頼性を高める ことにもなります。
テストの信頼性をチェックするための、さまざまな数値
信頼性 って、最初に教えていただいた信頼性と妥当性のやつですか。
そうです、 信頼性は、スコアの安定性を表す概念 です。信頼性の高いテストでは、そのテストを仮に何回受けたとしても、多少のブレはあっても、いつもほぼ同じ点数になります。この信頼性は、 信頼性係数 という、0から1の間の数値で表せます。
どれぐらいの値がいいテストなのですか?
絶対的な基準はありません。 0.8程度を目安とすることが多い ですが、受検者の集団や、測定したい特性によって異なります。テストの利用目的や使い方にもよります。今回は、やはり0.8以上はあってほしいですね。
学校の先生がテストを自作する場合の信頼性はどの程度でしょうか。Frisbie (1988)は、平均的に0.50程度であると述べています。これは、スコアを左右する要因のうち50%が測りたい能力とは無関係の誤差、つまり「たまたま」できたりできなかったりする部分であるということです。この程度の信頼性では、そのテストのスコアのみに依拠して評価を行うのは危険といえます。しかし実際には、学校の先生は生徒一人ひとりを日々観察し、宿題や成果物など他の情報も利用して総合的に成績をつけていると考えられます。個々の情報の信頼性は高くないかもしれませんが、それらを統合することによってトータルな評価結果の信頼性を高めるという作業を(無意識にせよ意識的にせよ)行っていることになります。
ちなみに、信頼性が高くなる条件として、次のようなものがあります。特に大事なのは、 相関と項目数 ですね。項目同士の相関や、項目とテスト全体の相関が高ければ高いほど、信頼性は高くなりますし、そういう相関の高い項目の数を増やせば増やすほど、信頼性は高くなります。
- 項目同士の相関、個々の項目と全体得点の間の相関が高い
- 項目数が多い(ただし項目とテスト全体の相関がほとんど0の項目では効果は少ないし、負の相関がある場合はかえって信頼性が下がる)
- テストの出題領域が限定的(多様な要素を含むほど信頼性は低くなる傾向がある)
- 選択式などの客観的な形式の項目から成るテスト(記述式など個別採点を要する形式の項目は、採点基準の曖昧さ、採点者による結果のばらつきがスコアに含まれる場合、信頼性が低くなる傾向がある)
- 測定の対象となる集団において、テスト得点の真の値(各受検者が本来とるべき得点)のばらつきが大きい
- 測定したい特性以外の要因のスコアへの影響を減らす(受検者の動機付け、集中力、疲労、テストの慣れ、受検環境など)
相関が高いことと、項目数が多いことが大事なのですね。つまりそれって、似た問題がたくさんあるということですよね。友人にプレテストしたときに、「似たことばかり何度も聞かれた」と言われて困ったのですが、信頼性のためにはある程度は数を用意しないといけないのでしょうか。
はい。信頼性を確保するためには、項目はある程度の数は必要です。通常は項目数が多ければ多いほど、信頼性は高くなります。しかし項目数が多いほど受検者の負担は増しますので、現実的には、できるだけ相関の高い項目を許容範囲の数でまとめる、という感じです。
今回は、項目数は20個ぐらいが、許容範囲なのですね。
はい。それぐらいの数で、十分な信頼性係数の値になることを願っています。
そして信頼性係数と同時に、 「測定の標準誤差」 も確認します。この2つは互いにリンクしています。
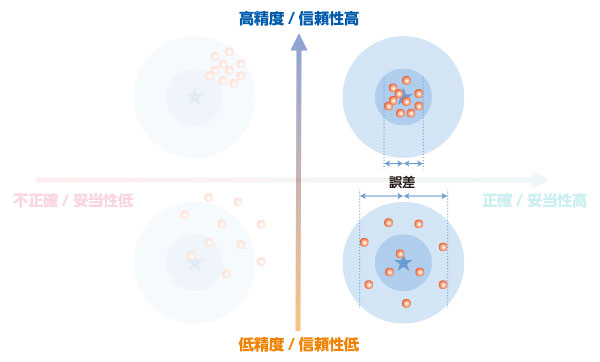
ダーツの絵を思い出してください。信頼性が高いものは、的の当たる位置が集中していましたよね。的の真ん中が 「真(しん)の値」
、すなわちその人の本当の得点とすると、何回投げてもだいたいその近くに当たります。 真の値からの「誤差」が少ない のです。
逆に信頼性が低いものは、真ん中の真の値を目指しても、投げるたびに大きく右に行ったり左に行ったりと、誤差が大きいのです。
真の値、ですか。
そうです。大事なことなので覚えておいていただきたいのですが、テストで測った測定値というのは真の値ではなく、 必ず誤差が含まれています 。マナブさんがあるテストで50点という点数を取っても、マナブさんの本当の能力、つまり真の得点が50点とは限らないのです。
必ず誤差があるのですか。じゃあテストする意味がないんじゃあ…なんて言っちゃいけないですね。えっと、だから、そのなかでもなるべく誤差が少なくなるようにテストを作りましょうということですよね。
そのとおりです! 絶対に誤差はありますが、真の得点が50点の場合、実際の得点が49~51点くらいに収まるテストなのか、40~60点くらいに広くばらつくテストなのかでは、全然違いますからね。 真の得点に対して実際の得点がどの程度ばらつくかを表した指標が、測定の標準誤差です。
たとえば、真の得点が50点で実際の得点が49~51点のテストは、±1なので、測定の標準誤差は1になります。実際の得点が40~60点のテストは、±10なので、測定の標準誤差は10となります。
測定の標準誤差が小さいほど信頼性は高くなります。測定の標準誤差は、何点程度ばらつくかを具体的に表したものであり、信頼性係数は、誤差の大きさを0~1の割合で表したものです。
このように考えたとき、テストを受ける方やその結果を使う方も、50点という結果をただの「点」だけで見るのではなく、 誤差を含んだ「区間」 のような見方もできるようになれば、とても素晴らしいことです。
点数を点として見ない? 斬新だなぁ…。
もしテスト得点に含まれる誤差が正規分布に従って無作為に生じるとすると、「真のテスト得点」から測定の標準誤差±1個分の範囲に「実際の得点」が入る確率は約68%、測定の標準誤差±2個分の範囲に「実際の得点」が入る確率は約95%となります。
つまり、たとえば測定の標準誤差が2.5のテストがある場合、真の得点がX点の人がこのテストを受けたら、約68%の確率でX±2.5の間の得点になりますし、約95%の確率でX±5(2.5×2)の間の得点になります。下の2つの図は、X=50としてこの状況を描いたものです。
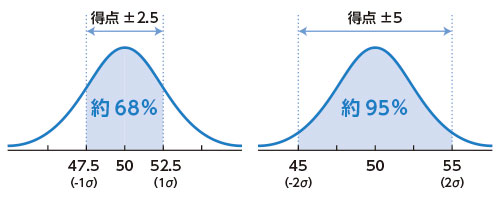
この性質を利用して、 その人の真の得点を「実際の得点±2.5」「実際の得点±5」のように範囲で推定することができ
、こうして得られる範囲のことを、それぞれ真の得点に関する 「68%信頼区間」「95%信頼区間」 といいます。
ただしこの信頼区間は、誤差を含んでいる実際のテスト得点での数値(推定値)なので、1回のテストで求めた信頼区間が必ず真の得点を含むとは限りません。仮に何度も同じテストを受けてもらったとして、その都度信頼区間を計算した場合、そのうちの68%(あるいは95%)が真の得点を含んでいる、という意味合いがあります。
テスト理論に基づくデータ分析では、 因子分析 といって、テスト項目のまとまりの確認も重要です。用意している項目が、 共通して同じものを測っていると見なせるか 、事前に決めた 構成概念から考えられる仮説どおりのまとまりになっているかどうか といったことを確認します。これは、テストスコアが適切に解釈できるかという 妥当性の確認作業 の1つです。そのあとの、テスト仕様やフレームワークとの整合性の確認も、妥当性の確認ですね。
因子分析はテスト開発における一般的な分析で、データから項目同士がどのようにまとまるかを調べるための分析手法です。
項目間の相関関係の背後に、何か共通して存在する変数(これを因子と呼びます)があると仮定します。その値の高低によって項目間の相関関係がうまく説明できるかどうか、また、できるとすればいくつの因子を仮定すればよいか、といったことを因子分析によって調べます。
因子分析には、主に「探索的因子分析」と「確認的因子分析」の2つの目的に応じた分析があります。
探索的因子分析
変数の相関関係がいくつかの因子で説明・解釈できるか、因子間の関係はどうなっているかを探る
確認的因子分析
仮説に基づく因子構造にデータが適合するかを確認する
データ分析でも信頼性と妥当性が大事なのですね。というか、テスト作りでは一貫してこれらが本当に大切なのですね。
いいですね、マナブさん、本当に素晴らしいですよ! もうマナブ先生とお呼びしましょう。ではマナブ先生、実際に分析に入りましょう!
いやいやいや、僕が先生って、やめてください…。
いろいろな数値を計算したり、グラフにしたりして、分析結果をさまざまな角度から見ながら、項目の性能を吟味していきます。判断に迷うことも出てきたりして、一筋縄で行く作業ではありませんが、次回までには仕上げたいですね。
先生、またハードルの高そうなことを、さらっとおっしゃっていますよ…。
あれ、そうですか? 分析とはそういうものですし、だから、やりがいも大きいですよ。一緒に楽しみましょう!
近年ビッグデータといって大量のデータを蓄積できるようになってきたこともあり、今まで以上にデータの活用が重視されています。ビジネスの世界でも適切なデータ分析ができる人材が求められ、「データアナリスト」や「データサイエンティスト」は、今注目の職種の1つかもしれません。
彼らはプログラマーのように分析のためのスクリプトを書き、統計ソフトが出力する大量の表やグラフの中から、有益な情報を読み取ります。
ただし、実際に費やす時間と労力は、データ分析の「前処理」といわれている、分析前のデータの確認や形式統一などの整理作業が大半です。
たとえば、同じ会社名が「株式会社ABC」「(株)ABC」「ABC」「エービーシー」などさまざまに表記されていると同じデータとして扱われませんので、これらはすべて同じ表記に統一する必要があります。あるいは、1か2のどちらかの数値しか入るべきでないデータであれば、それ以外の値が入っていないかを確認し、もし違う値があればそのデータが意味するところを確認し(欠損値か、入力間違いかなど)、適切な値に変換する必要があります。
これらの前処理はいずれも地味ながら分析の精度に関わる重要な作業です。データ分析の実態としては、データ分析業務の7割か8割を、この前処理が占めていることになります。
- 予備実査のデータ分析を通じて、できるだけ信頼性が高い(測定の標準誤差が小さい)テストになるよう、適切な項目を取捨選択する。
- 信頼性とは、テストの測定精度を表す概念である。
- 測定の標準誤差とは、真の得点に対して実際の得点がどの程度ばらつくかを表した指標である。
プロフィール
加藤 健太郎
■専門領域
心理測定学および統計学
テスト理論に基づくテスト開発および関連する統計的手法の研究開発(サイコメトリシャン)
■やっていること
ベネッセ教育総合研究所におけるアセスメント研究開発
アセスメント事業の開発・運用サポート(ベネッセ、その他受託案件等)
最新の測定技術に関する情報収集・研究(学術論文・専門書の執筆、学会発表)
学術誌の論文査読委員
講演・研修会講師
大学非常勤講師
「テストについての正しい知識と、テストへのポジティブな興味関心をもっていただきたいと願っての連載です。テスト結果の数値の意味についても説明していこうと思います。次回以降もぜひ読んでみてください!」



